 Project Background
Project Background
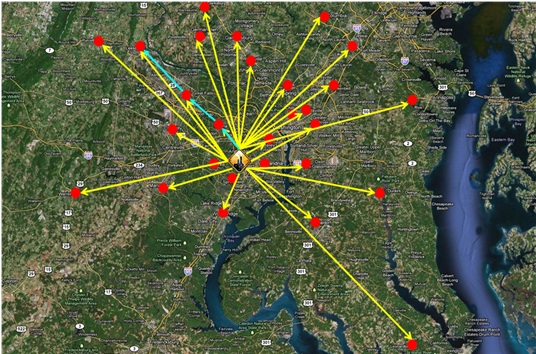
In the fall of 2010 and spring of 2011, the Washington Post (WP) requested graduate students from the Department of Systems Engineering and Operations Research at George Mason University (GMU) to assist their Springfield, Virginia plant with determining an efficient method to produce cost savings in their shipping and receiving operations. Past GMU teams performed data collection and process evaluation, resulting in recommendations for efficiency gain which have since been implemented in the Shipping and Receiving Department. In the fall of 2011, the WP customer asked to expand the problem scope to determine an efficient method to produce cost savings within their Circulation Department. Given the recent decline of subscriptions, the Washington Post Circulation Department (WPCD) is looking to find the most cost effective truck run schedule, the most efficient truck fleet combination, the most cost effective driver schedule, and the optimal driver staffing plan needed to deliver Daily and Sunday papers to their twenty-seven warehouses to support on time delivery of their newspaper products to residences in the Washington, D.C. area.
Project Objective and Scope
The team's objective is to maximize the efficiency of the truck run schedule in the Circulations Department at the Washington Post's Springfield, Virginia plant. The scope of this project deals with daily truck scheduling, including truck type and delivery route, needed to facilitate the movement of pallets of six different product types from the Springfield, Virginia production facility to their twenty-seven warehouses to enable timely delivery of Daily and Sunday papers to resident subscribers. The efficiencies that are identified are intended to set the basis for future work in reducing the operating costs associated with fleet makeup and driver staffing plan.
Project Work
Through data collection and discussions with the Washington Post customer, the Team documented the existing WPCD system structure and behavior and created a truck routing model to produce efficient truck run schedules based on estimated daily newspaper product volume and warehouse timing constraints. The Team first captured the WPCD system's needs and current state of operation in order to fully understand the system of interest.
The truck routing model was then formulated as a Time-Space network Integer Program. This formulation allowed the team to model the movements of product as it is produced through the network with constrained availability of trucks while reducing the cost. The model was built to accept estimated daily product volume and warehouse demands. The model combines shipments into one route that serves multiple distribution centers where it is feasible and cost effective to do so. Once the model was complete, testing, evaluation, and sensitivity analysis indicated that it did in fact accurately model the WPCD system.
A fleet mix model was then implemented, using the truck routing model as an engine. A linear regression on the data that was provided by the WPCD was performed to project the product demand in the future. The projected number of pallets was used as an input to the truck routing model, while the number of trucks available was left unconstrained.
Project Results
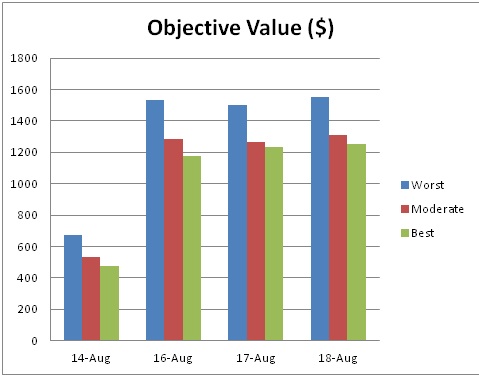
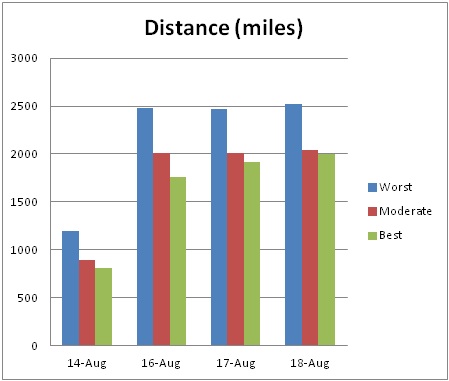
In all test cases we were able to find solutions that were dramatically better than shipping according to the "spoke" model (i.e. routes only from the production plant to the distribution centers and back). Considering only gas and leasing costs, our model shows savings on average of around $300 per day. Also, the solutions show a drop in total driving mileage around 400 to 500 miles per day. Our solutions also increase the utilization rate of trucks (i.e. shipping the same number of pallets with fewer trucks). While labor costs were not taken into consideration in our model due to the driver scheduling system The Washington Post already has in place, our results suggest that dynamically routing trucks generates significant savings in labor as well.
Gas and leasing cost savings come from efficiently and dynamically "bundling" orders together depending on how many pallets are needed at each distribution center. Given that there is sufficient time, it is almost always cheaper to have a single truck go to two different distribution centers than have two trucks going to each one separately. This bundling however is not obvious. In analyzing routing output from our model for three test cases, we found over forty instances of multi-distribution center tours and not one was ever repeated. The optimal routing will change from day to day depending on demand and any static system of scheduling will most likely be suboptimal.
Our team has identified significant cost savings for The Washington Post by efficiently and dynamically scheduling truck routes based on daily demands. The team has developed a proof of concept model that takes daily demand input and dynamically schedules truck routes to minimize fuel and leasing costs. The model employs a user-friendly Excel based front-end which interfaces with an integer programming model written in MPL and ultimately solved using the CPLEX engine.
While the team wrote the code for the front-end and model, CPLEX is a commercial grade optimization solver costing around $10,000 for a single license. Despite the initial cost of the software, we believe that our model identifies enough savings to justify implementation. In all test cases we were able to find solutions saving between $200 and $300 per day and around 400 to 500 driving miles. These savings alone justify the cost of a CPLEX license. In addition, our analysis does not include possibly the biggest driver of cost savings, labor. In all test cases our model produced solutions that increased the percentage of time that trucks remained at the production plant. This is an indicator that if a dynamic routing system is implemented, fewer trucks, and thus fewer drivers, will be needed per day.
Should The Washington Post decide to implement a dynamic truck routing system, we recommend that it be based on the time-space network framework. The mathematical formulation is easy to implement and straight forward to understand. The bulk of the work for implementing a time-space network is in the network generation phase before anything is sent to the optimization solver. Unless very powerful computing platforms such as server clusters are used, the network containing all feasible solutions is simply too big to handle. Generating the feasible arcs in the network in a controlled, intelligent way is critical to the model producing good solutions.